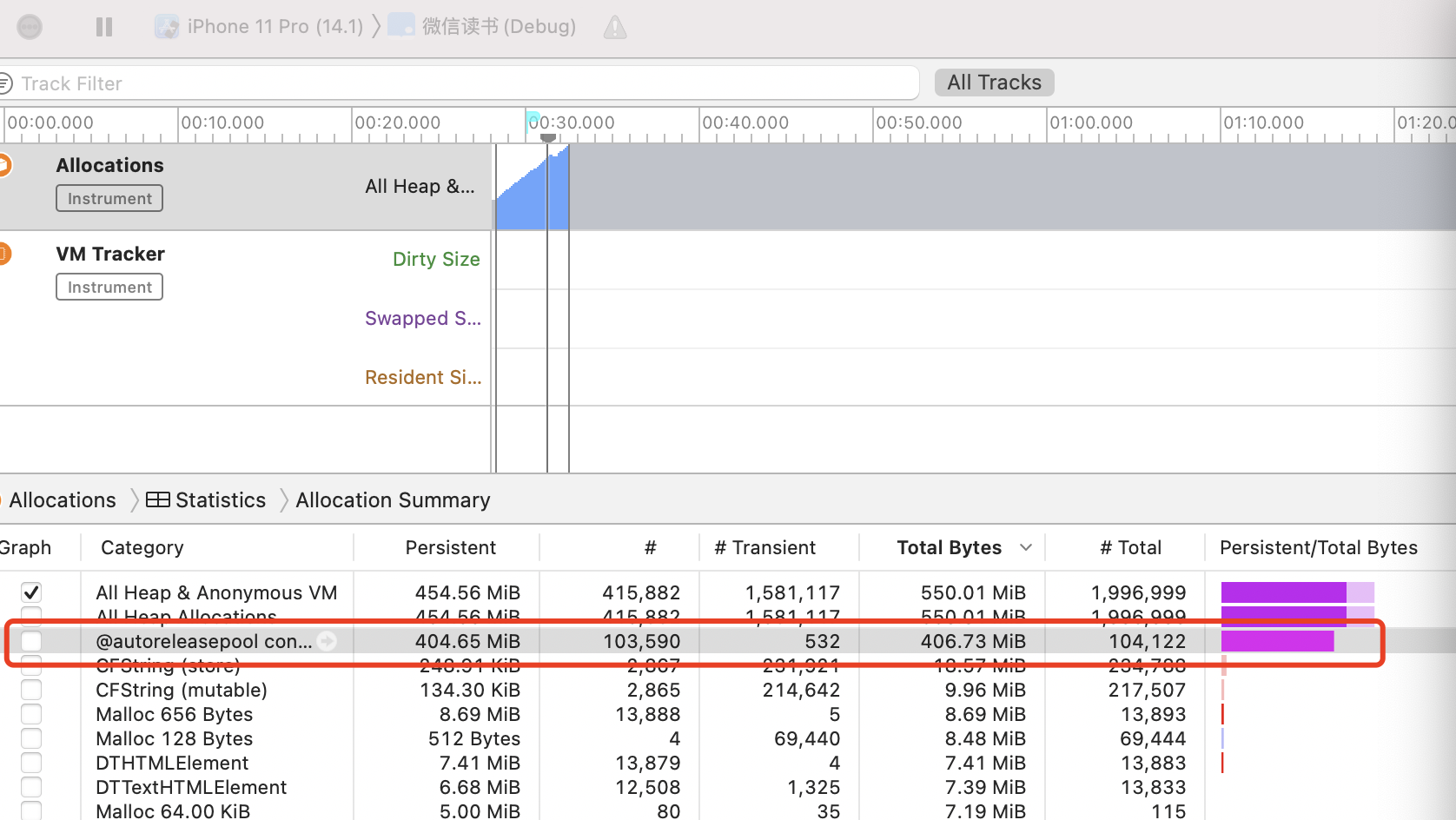
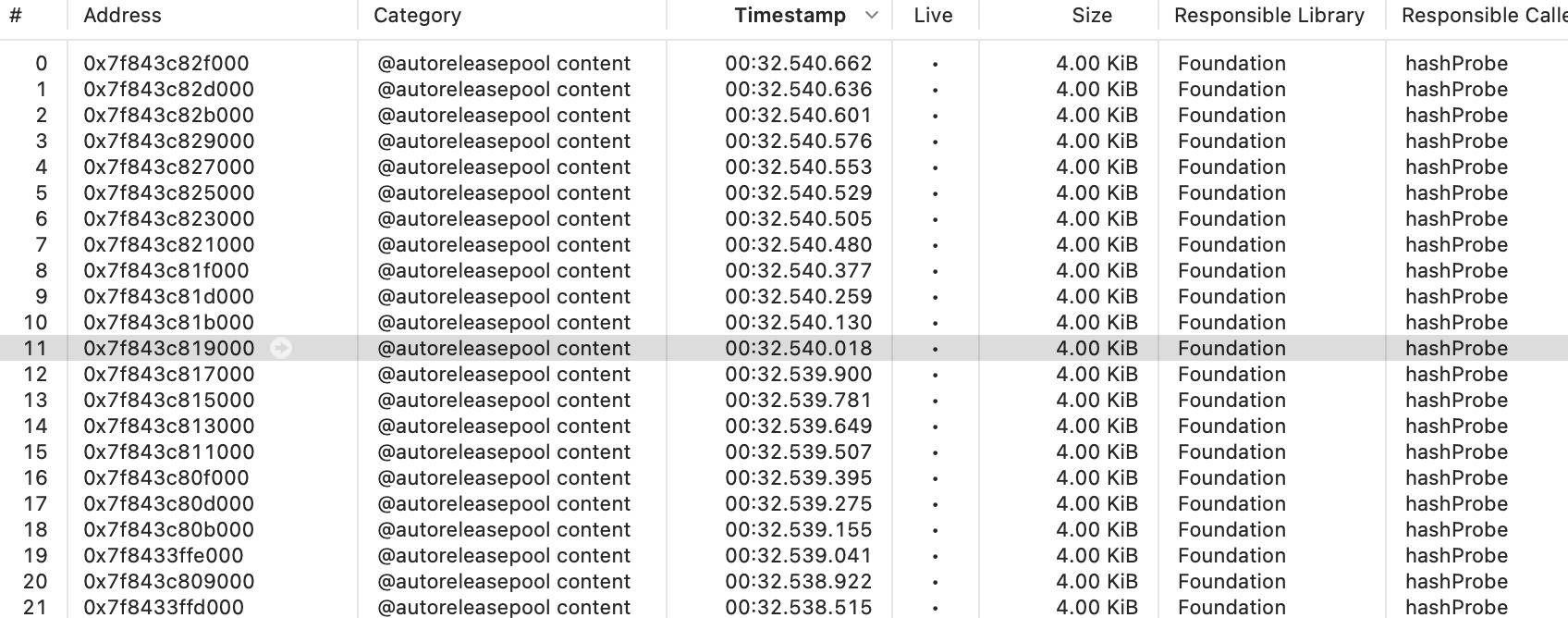
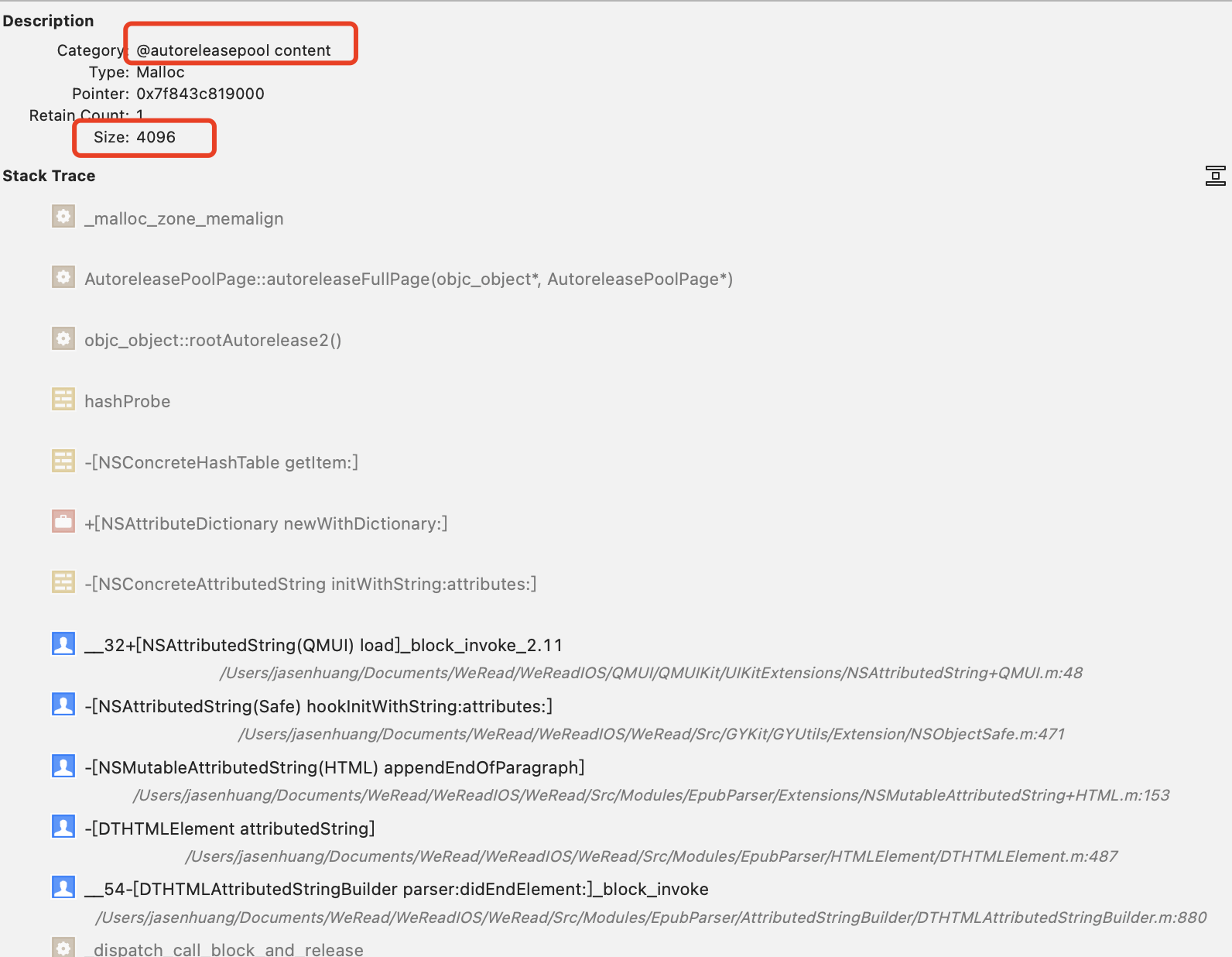
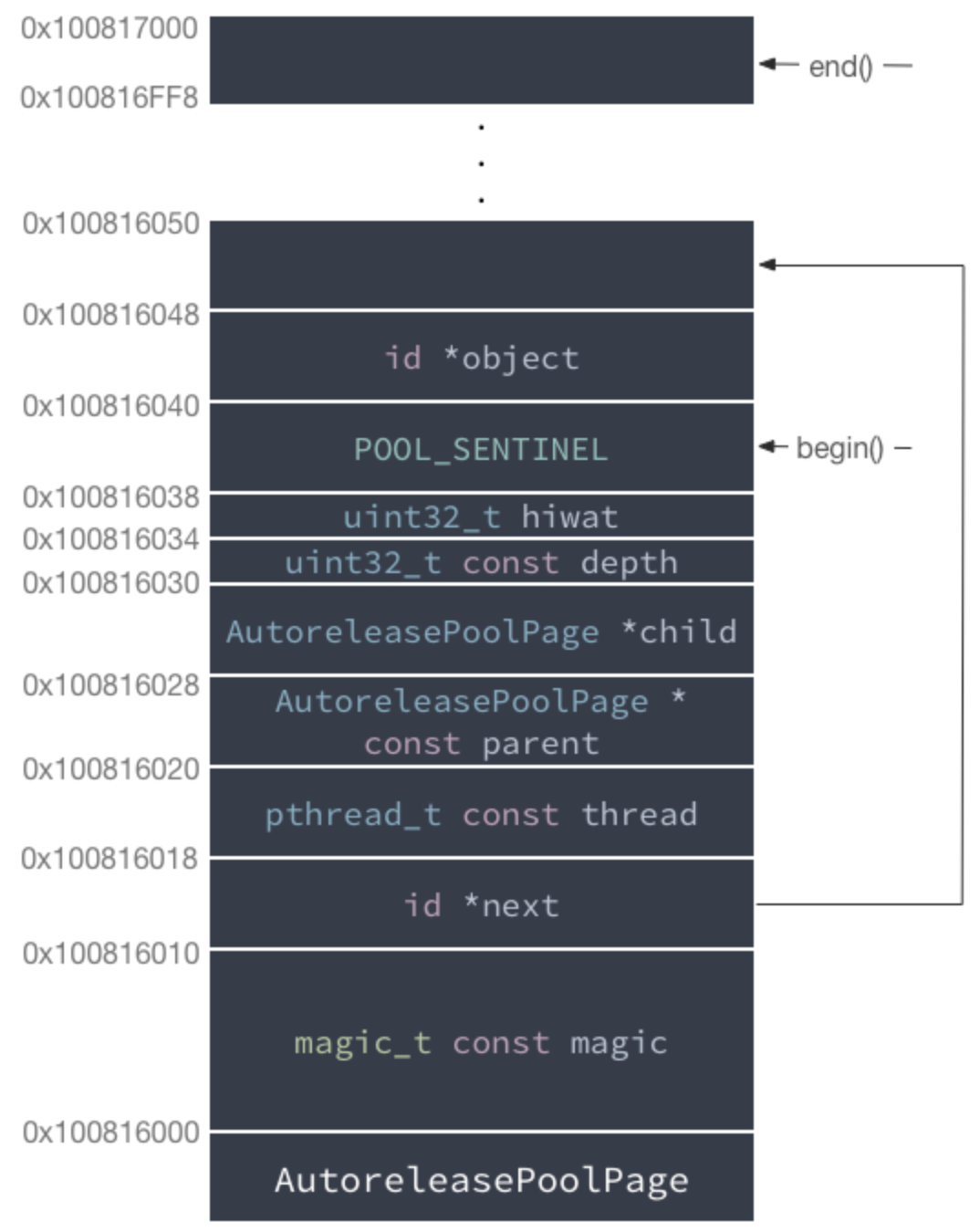
fishhook function with ObjC block :1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 原函数
int testFunc1(char* a, struct test_t b) {
return b.x + 1;
}
// hook
kk_fish_hook(@"testFunc1", (kk_replacement_function)^int(void *replaced, char* name, struct test_t rect) {
// 调用原函数
int(*origin)(char*,struct test_t) = (int(*)(char*,struct test_t))replaced;
int sum = origin(name, rect);
return sum;
});
// var_lit
kk_fish_hook(@"printf", (kk_replacement_function)^int(void *replaced, char * format, KKTypeList){
int(*origin)(char*,...) = (int(*)(char*,...))replaced;
return origin(format, KKVarList);
});
实现原理
block signature- 通过获取
block的signature(block的参数要与Hook的函数匹配)确定hook的函数原型ffi_cif
- 通过获取
libffi- 构造
ffi_closure返回_kk_ffi_closure_func - 用
fishhookrebind_symbols把函数调用重定向到_kk_ffi_closure_func _kk_ffi_closure_func里构造NSInvocation,把原函数replaced作为第一个参数传给NSInvocation,对block进行invokeWithTarget实现block调用
- 构造
如何hook带可变参数的函数 printf
- 因为可变参数无法传递,插桩代码后要调用回原函数直接枚举多个参数
KKTypeList+KKVarList另外通过汇编,保存栈指针和寄存器 + jmp 的方法也可以实现,然而就相对复杂很多了
- 因为可变参数无法传递,插桩代码后要调用回原函数直接枚举多个参数
源码
KernelKit 是源自于QQ邮箱/微信读书移动客户端项目多年开发经验提炼了出来的框架,封装了iOS、Macosx常用的底层API,涉及动态库,线程,内存,Crash, Hook, I/O, ObjC-ABI等内容,致力于为iOS、Macosx底层操作系统接口提供更好的API封装,持续更新中。